고정 헤더 영역
상세 컨텐츠
본문
계속 커져만 가는 데이터 홍수 속에서, 우리는 시간별로 데이터를 정돈하고자 타임스탬프라는 것에 의지합니다. 하지만 시간스탬프의 0.001초 정도까지의 디테일은 오히려 분석에 방해가 될 수 있어요. 예를 들어, 유저 회원가입의 트렌드를 살펴보고 싶다고 가정해 봅시다. 아마, 회원가입이 발생한 시간에 따라 총 회원가입 수를 살펴보겠죠. 아마도 분석에는 회원가입 이벤트가 가지고 있는 타임스탬프를 살펴볼 텐데, 아마 그 타임스탬프가 가지고 있는 모든 정보를 필요로 하지는 않을 겁니다. 연별, 월별, 일별 회원가입 수를 보고자 할 수는 있어도 시간별, 분별, 초별 회원가입의 경향을 파악하는 건 오히려 당신의 분석을 괴롭게 만들 겁니다. 이럴 때 아주 유용하게 사용되는 기능이 바로 DATE_TRUNC() 함수 입니다. 이 함수를 사용하면 여러분이 필요로 하는 시간 간격에 맞춰 시간을 반올림할 수 있어요.
타임스탬프: 얼마나 보기 좋지 않게 생겼는지 보세요
타임스탬프는 길기도 길고, 정말 많은 정보를 담고 있어요.

우리를 구조해 줄 DATE_TRUNC()
타임스탬프의 원치 않는 부분을 제거하고 싶다면, DATE_TRUNC(‘[interval]’, time_column) 안에 해당 타임스탬프를 넣어 버리세요. time_column는 끝을 잘라내고 싶은 타임스탬프가 담긴 열의 이름을 넣어주세요. ‘[interval]’은 어느 부분까지 정확하게 보여주고 싶은지를 적는 겁니다. 해당 함수를 통해서 잘라낼 수 있는 시간 단위는 아래와 같아요.
microsecond
millisecond
second
minute
hour
day
week
month
quarter
year
decade
century
millenium
위에서 보았던 타임스탬프를 ‘day’ 기준으로 자른다면, 결과는 다음과 같아요.
2015-10-06T00:00:00.000Z
그럼 ‘minute’을 기준으로 자른다면, 결과는 어떨까요?
2015-10-06T11:54:00.000Z
‘second’를 기준으로 자른다면 가장 근접한 초 값을, ‘hour’를 기준으로 자른다면 가장 근접한 시간을 보여주는 식입니다. 그리고 ‘week’을 기준으로 자르면, 그 주의 월요일을 보여줘요.
끝을 잘라 버린 타임스탬프로 시간에 따른 분석하기
DATE_TRUNC()는 시간 간격에 따라 정보를 합쳐서 보고 싶을 때 꽤나 유용하게 쓰입니다. Mode의 실습용 데이터 세트를 사용해서 시간에 따른 고객 회원가입 추세를 알아보도록 합시다. 아래의 쿼리로 시작해 볼게요.

이 쿼리의 결과는 다음과 같아요.
|
occured_at |
user_id |
|
|
1 |
2014-05-25 18:05:08 |
9526 |
|
2 |
2014-05-25 16:45:54 |
9523 |
|
3 |
2014-05-25 15:03:07 |
9531 |
|
4 |
2014-05-25 12:46:22 |
9527 |
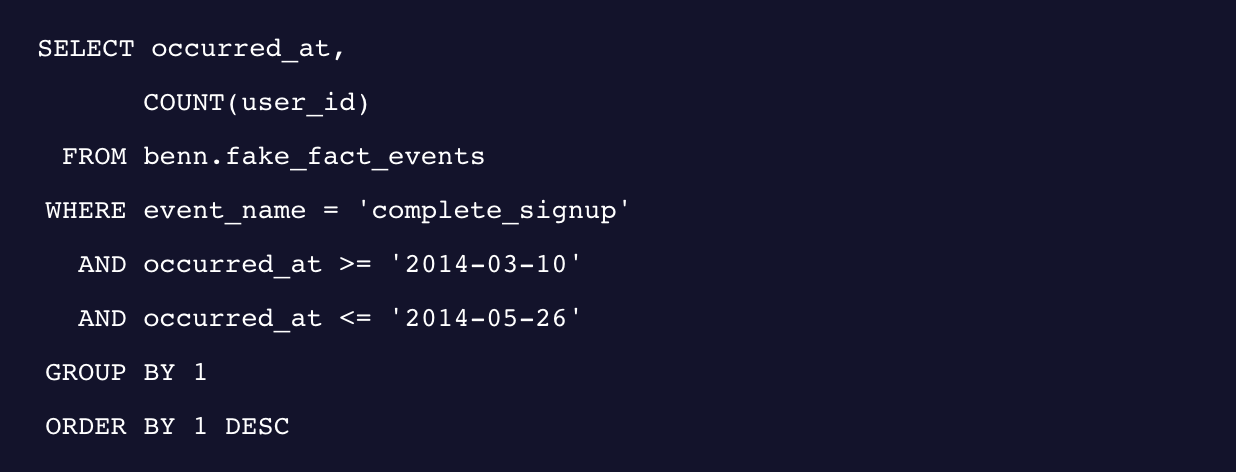
여러분도 아실 것 같은데, 이런 종류의 시간 데이터는 데이터를 합쳐 보기엔 그닥 좋지는 않아요. 타임스탬프를 기준으로 GROUP BY 를 실행하면 어떻게 되는지 볼까요?
|
occured_at |
count |
|
|
1 |
2014-05-25 18:05:08 |
1 |
|
2 |
2014-05-25 16:45:54 |
1 |
|
3 |
2014-05-25 15:03:07 |
1 |
|
4 |
2014-05-25 12:46:22 |
1 |
비록 이 시간스탬프가 0.01초까지의 정보를 담고 있는 것은 아니지만, 여전히 유의미한 트렌드를 파악하기엔 너무나 많은 정보가 있죠. 그래서 이번에는 회원가입이 발생한 날짜를 기준으로 occurred_at 이벤트를 살펴보려고 해요. 날짜를 기준으로 볼 거니까 타임스탬프에서 날짜 이후의 데이터는 날려 버릴려고요. 아래 전체의 쿼리문을 봅시다.

위 쿼리의 결과는 다음과 같을 겁니다.
|
occured_at |
count |
|
|
1 |
2014-05-25 00:00:00 |
9526 |
|
2 |
2014-05-25 00:00:00 |
9531 |
|
3 |
2014-05-25 00:00:00 |
9524 |
|
4 |
2014-05-25 00:00:00 |
9525 |
이렇게 뒷 부분이 잘린 타임스탬프를 기준으로 데이터를 합쳐보는 것은 가능하겠죠. 2014년 05월 25일에 몇 개의 회원가입이 발생했는지 이제는 확인할 수 있겠어요.
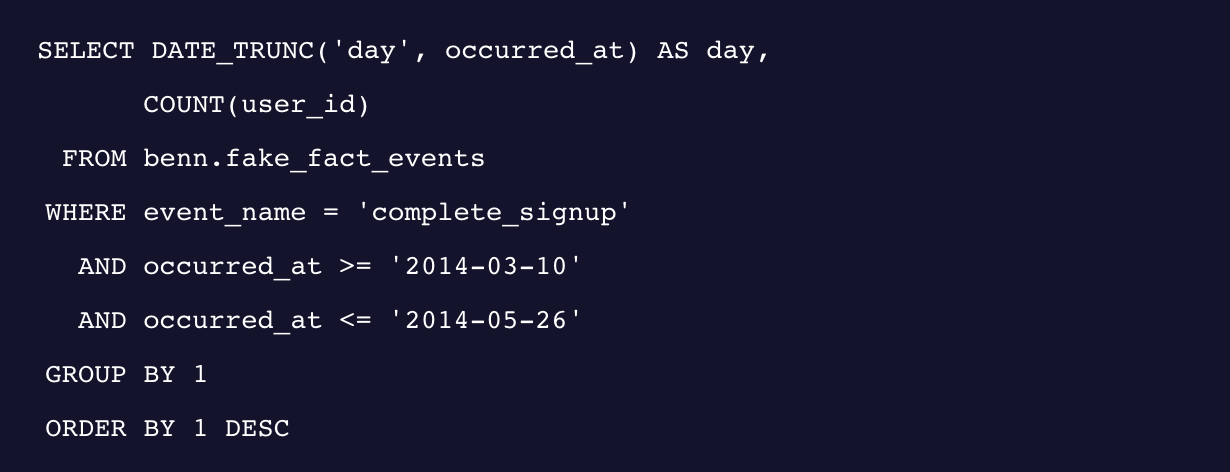
우리가 ‘day’를 기준으로 타임스탬프의 뒷 부분을 날렸기 때문에, 위의 쿼리는 일자별로 총 몇 개의 회원가입이 발생했는지 보여줄 겁니다. 그리고 그런 쿼리 결과를 시각화하면 아래와 같은 그래프로 나타낼 수 있고요.

보니까 회원가입 매 주말마다 급 하락하네요. 이 그래프는 한 주의 회원가입 추세를 강조하기 때문에, 아직까지는 주차별로 회원가입의 경향을 파악하기 어려워 보이네요. 지난 몇 개월 사이에 회원가입이 증가했는지? 주의깊게 살펴봐야 할 하락 포인트가 있었는지? 이 두 가지의 질문에 답을 하려면 타임스탬프를 ‘day’ 기준이 아니라 ‘week’ 기준으로 뒷 부분을 날려보세요.
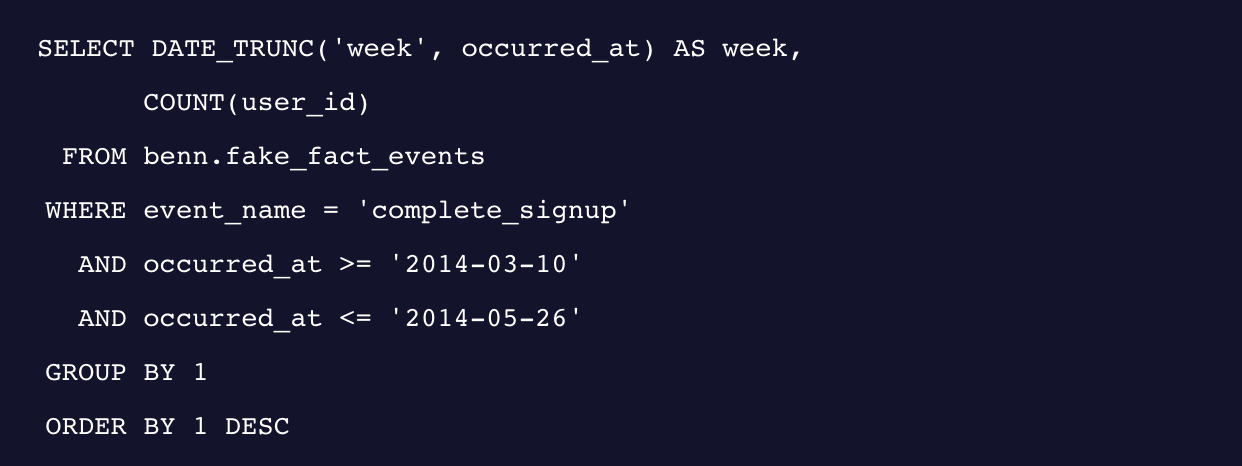
이제는 주차별에 따른 데이터를 시각화해서 볼 수 있겠네요.

한 주의 모든 데이터를 포함하느라 상승 및 하락세가 컸던 그래프를 봤던 것에 비해, 이제는 명확한 결론을 내릴 수 있습니다. 시간에 따른 회원가입은 전반적으로 안정적인 추세를 보였고, 3월 말쯤 살짝 하락세를 보였으나 다시 수치가 뛰어 올랐어요.
지금까지 살펴본 것처럼 DATE_TRUNC() 함수는 시간을 다루는 데이터를 합쳐서 보고 싶을 때 정말 유용하답니다. 타임스탬프를 반올림하고 싶을 때 DATE_TRUNC() 함수를 사용하세요. 반올림 된 타임스탬프를 사용해 데이터를 집계하면 일별 구매량, 초당 발송된 메시지의 수와 같이 시간별 트렌드를 살펴볼 수 있어요. DATE_TRUNC() 함수는 2개의 요소를 필요로 합니다. 우리가 뒷 부분을 날리고 싶어하는 시간 단위와 지저분한 타임스탬프가 담긴 열의 이름입니다. 아래 예시를 보면 첫번째 행은 원래의 타임스탬프를 나타내고, 두번째와 세번째 행은 반올림된 타임스탬프를 보여줍니다.
쿼리문:

쿼리 결과:

'자료 번역 : SQL' 카테고리의 다른 글
| SQL에서 시간 데이터 다루는 법 (1) | 2021.01.09 |
|---|---|
| 대표적인 윈도우 함수 6가지 알아보기 (1) | 2021.01.08 |
| SQL CTE를 잘 활용하려면? (3) | 2021.01.06 |
| 서브 쿼리의 종류에는 무엇이 있을까? (1) | 2021.01.04 |
| SQL 내 집계 함수 vs. 윈도우 함수: 유사점과 차이점 (0) | 2021.01.03 |




